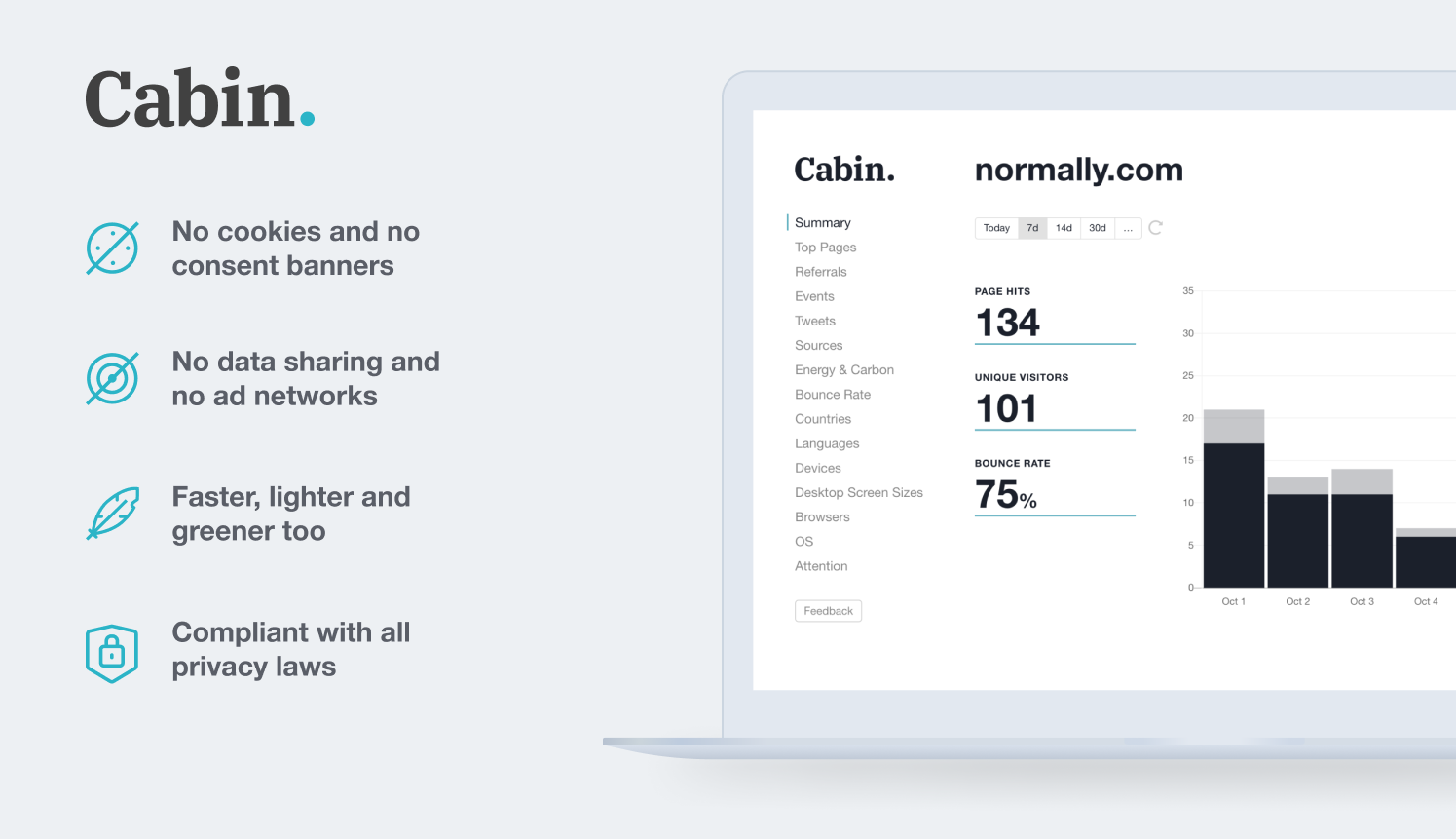
Cabin is a privacy-first, carbon-aware web analytics service. Built from the ground up on three core principles of respecting visitors’ privacy, respecting the environment and having a beautiful product.
It is claimed that we generate 2.5 trillion megabytes a day. Though unevenly generated, that’s on average 320MB per day for each human on earth.
This is inevitably going to increase. Network transfer and storage have become seemingly limitless yet they use electricity and therefore have a CO2 cost to our planet. Do we need all of this data? Most likely not.
Companies can be mindful of data they collect, store and share. Not only for energy and cost savings, but also to improve privacy for their customers at the same time.
Cabin Analytics has been developed at Normally, a research and design studio based in London. It was born out of coinciding and long running expeditions around data, privacy and also the carbon footprint of digital products and services.
Cabin is a privacy-first, carbon-aware web analytics service. Built from the ground up on three core principles:
- Respect visitors’ privacy
- Respect the environment
- Build a beautiful product.
What started as ‘how can we make a simpler product than Google Analytics?’ quickly turned into ‘how can we make the most private and environmentally friendly web analytics?’
Cabin has now been in beta for 18 months, logging around 100M page visits. Switching to Cabin can help reduce the carbon footprint of your website.
Optimising energy usage
To reduce energy consumption we made a script that’s 16x smaller than Google Analytics. In the beta alone we’ve saved over 2 terabytes of data transfer compared to Google Analytics[2]. The script is small because we only collect the minimum data to run our dashboard.

We became obsessed with benchmarking, to the nanosecond, slowly optimising the service to operate on the smallest footprint, optimised for low CPU and Memory usage. This allows us to utilise low cost, low energy servers and also span across multiple cloud providers.
We’ve harnessed serverless technology – servers that are only used when necessary, unlike always-on servers to save on energy costs. We also queue and batch visits, which means we can minimise the data we transfer and the amount of compute we use.
Our serverless database only holds 7 days of data, the rest is warehoused for less frequent access at a lower cost. That means our live database has remained less than 350MB throughout our beta.
To help users analyse their own carbon usage we’ve built an integrated tool that keeps track of your webpages and inspects their carbon impact. User’s can quickly spot issues, un-optimised images, unused scripts etc. You can try it here. How green is your website?
Privacy first
From the start, we wanted to avoid using cookies. Cookie consent forms on the web are a broken concept. They mislead users and are often badly implemented. There is also an uptake of ad-blockers which prevent cookies from functioning, some of which are now built into browsers.
By removing cookie banners, privacy isn’t a choice, it’s on by default. No more opt-outs and ad blockers means higher accuracy analytics compared to other services.
The Unique Identifier problem
Usually, web analytics services store a cookie on your machine with some kind of unique identifier (UID). In the case of Google Analytics, your UID is the same across all websites you visit. This means that Google can follow your movements across the web from site to site. All this data can be connected. Google doesn’t sell your data, but they use it to help advertisers target you – as they know a hell of a lot about you.
UIDs are the glue that allows Google to query user behaviour across all of the rows in the database. So if we remove this UID, there’s no way of connecting page visits… or so you’d think.
At Normally we’ve spent years exploring data privacy. We learned early on that data doesn’t need a UID, IP, name, address or date of birth to identify someone. Identification can be achieved simply by observing patterns of behaviour.
Digital fingerprints, made up of these attributes can be woven together to spot patterns of behaviour with similarities. The team at Cabin can actually identify a user in other places in the database quite easily, and eventually, maybe in real life.
The unique visitor problem
Without a unique identifier, it becomes tricky to tell if a visitor has been to your website before. Some privacy focussed analytics obfuscate the IP or hold a temporary fingerprint to solve this, but we found a better way:
Each time a visitor sends a request to Cabin it is cached in their browser just like any other request, such as a gif, a font or a css file. The next time they make the same request, the browser automatically sends a last-modified header to Cabin. Just the existence of this header implies they have visited before – and that’s all we need to know. No IP addresses, unique identifiers or browser fingerprints.
How Cabin protects privacy
We built our own data model for Cabin using an aggregated non-relational technique. Simply put, each domain we serve essentially has daily tallies for each attribute (browser, device etc…) and they aren’t linked.
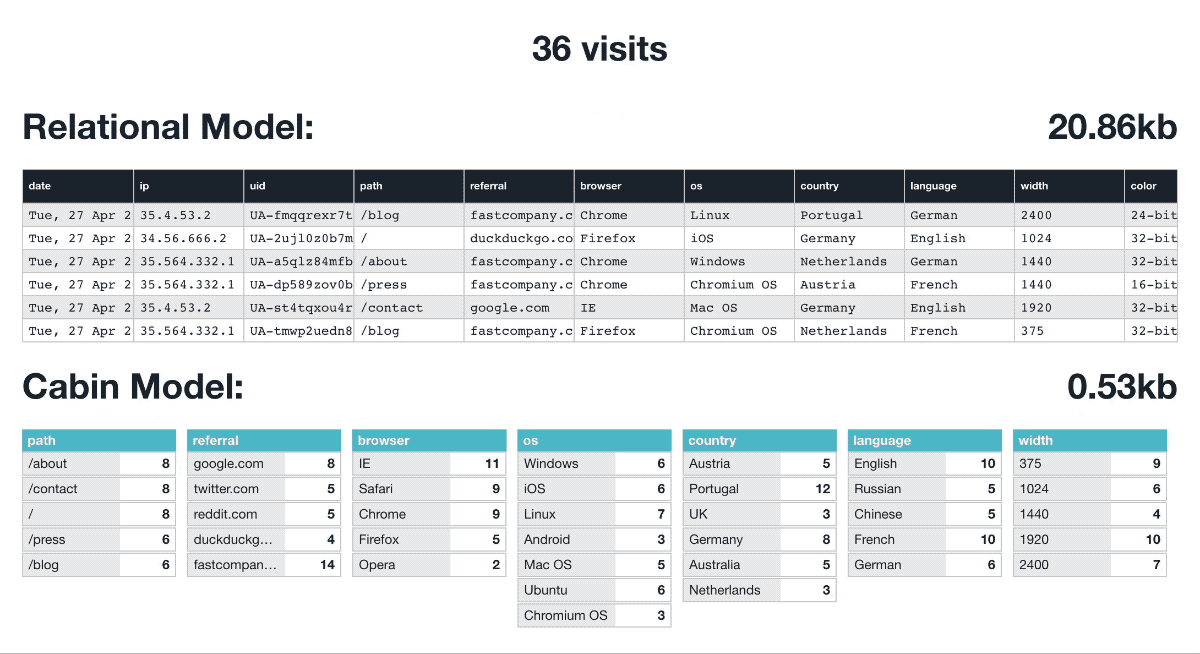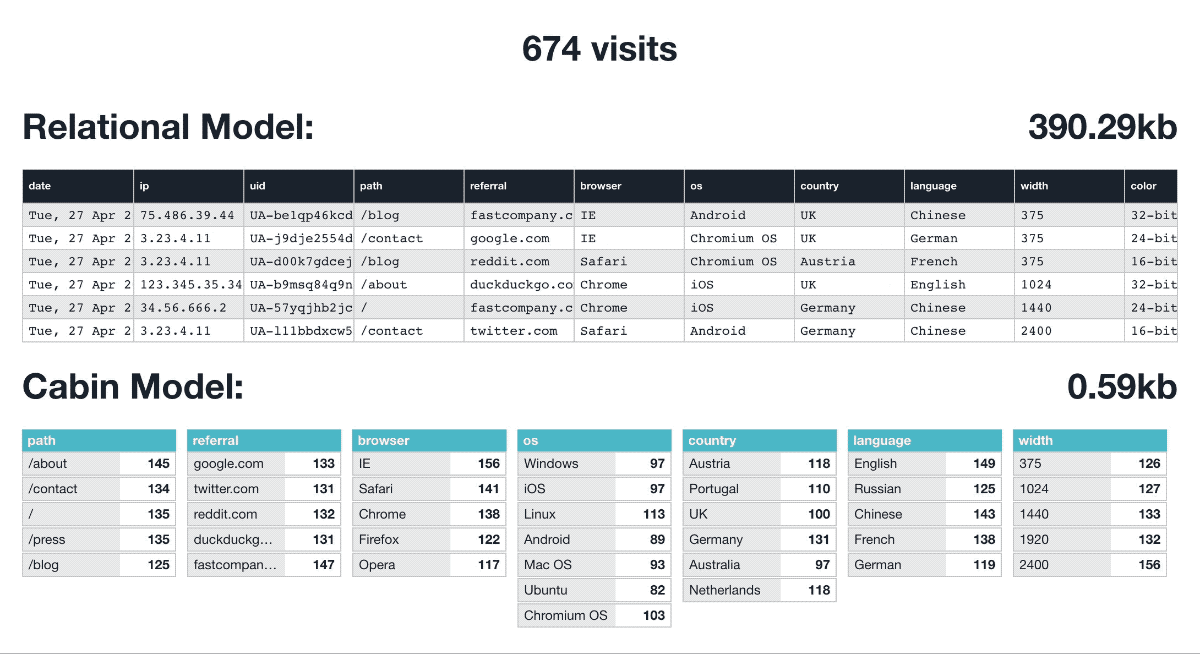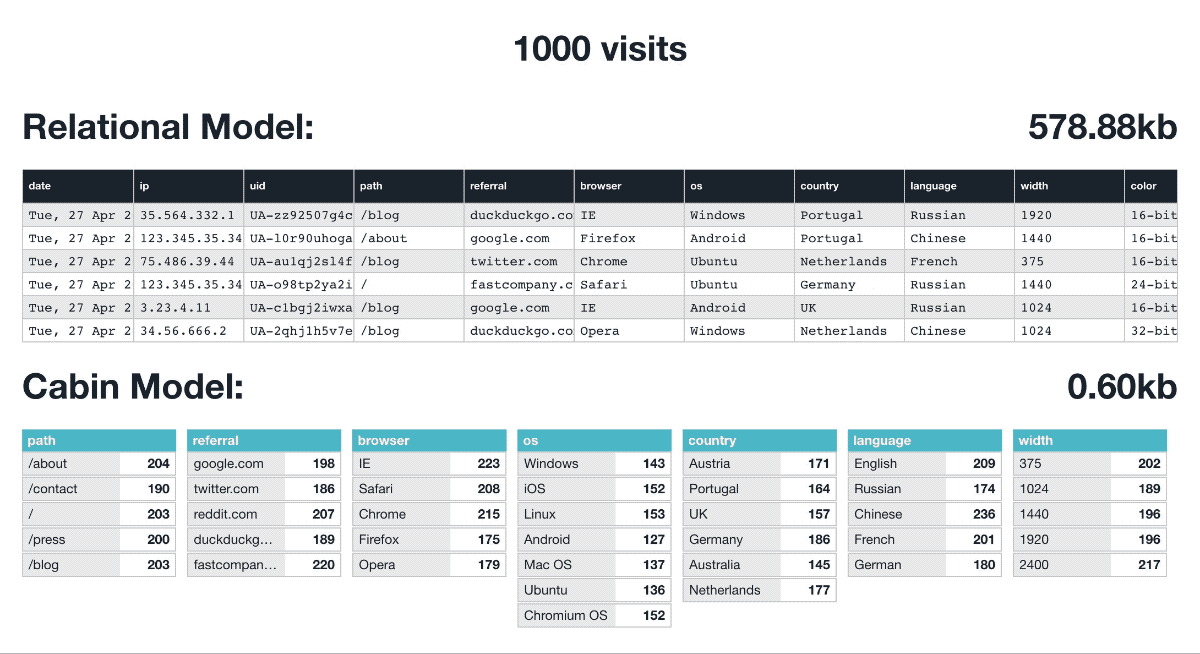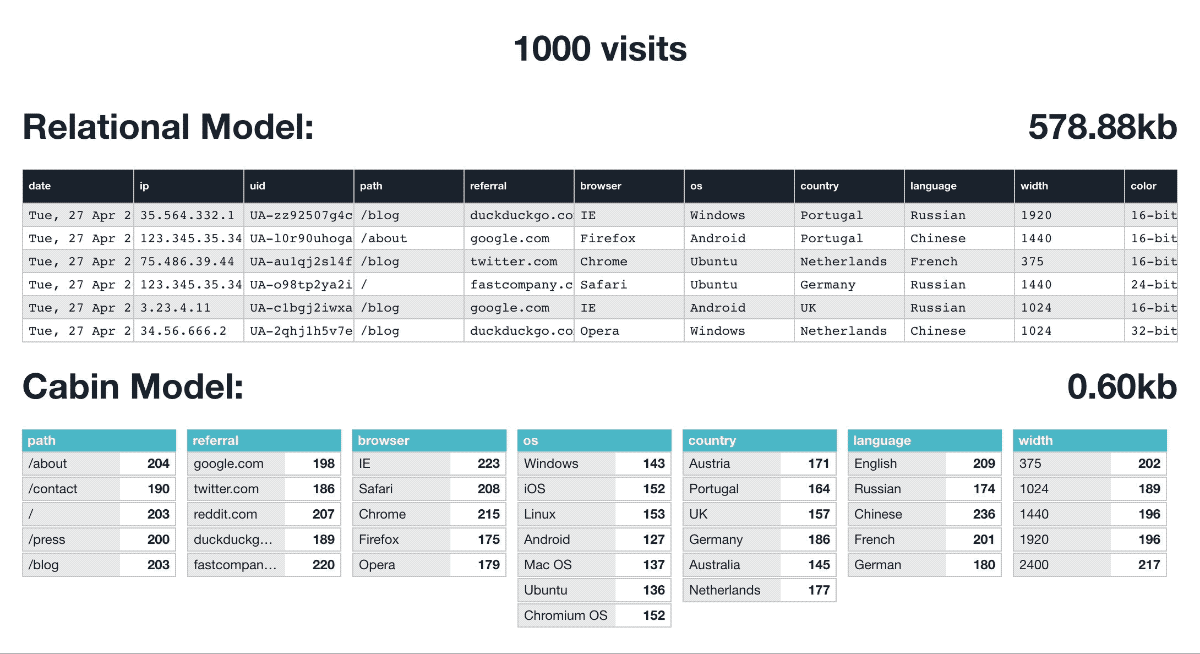
It’s now impossible to say that User A was from Portugal and using Chrome as they have no relational bearing.
This privacy is baked into our data model regardless of encryption or cloud security. The data is useless for targeting or identifying users. This also has tremendous storage saving ability and at the end of each day, it’s wrapped up as JSON files, ready to serve your dashboard directly without database interrogation.
There are some sacrifices we had to make, including the inability to pivot the data on a certain attribute. And when we add new features, we have to think carefully if it will fit in our model. If not, can it be achieved without jeopardising the privacy of the visitor?
Cabin is currently in Beta and will be launched early next year, you can sign up on withcabin.com. We hope to continue exploring how to design and build beautiful but accessible digital products that are better for the environment as well as data privacy
About
Normally is a research and design studio in London, fascinated by data and making things normally. See more at normally.com